Phân tích phương sai một yếu tố ( còn gọi là oneway anova) dùng để kiểm định giả thuyết trung bình bằng nhau của các nhóm mẫu với khả năng phạm sai lầm chỉ là 5%.
Ví dụ: Phân tích sự khác biệt giữa các thuộc tính khách hàng (giới tính, tuổi, nghề nghiệp, thu nhập…) đối với 1 vấn đề nào đó (thường chọn là nhân tố phụ thuộc, vd: sự hài lòng).
Một số giả định khi phân tích ANOVA:
– Các nhóm so sánh phải độc lập và được chọn một cách ngẫu nhiên.
– Các nhóm so sánh phải có phân phối chuẩn or cỡ mẫu phải đủ lớn để được xem như tiệm cận phân phối chuẩn.
– Phương sai của các nhóm so sánh phải đồng nhất.
Lưu ý: nếu giả định tổng thể có phân phối chuẩn với phương sai bằng nhau không đáp ứng được thì bạn có thể dùng kiểm định phi tham số Kruskal-Wallis sẽ để thay thế cho ANOVA.
Ví dụ: Phân tích sự khác biệt giữa các thuộc tính khách hàng (giới tính, tuổi, nghề nghiệp, thu nhập…) đối với 1 vấn đề nào đó (thường chọn là nhân tố phụ thuộc, vd: sự hài lòng).
Một số giả định khi phân tích ANOVA:
– Các nhóm so sánh phải độc lập và được chọn một cách ngẫu nhiên.
– Các nhóm so sánh phải có phân phối chuẩn or cỡ mẫu phải đủ lớn để được xem như tiệm cận phân phối chuẩn.
– Phương sai của các nhóm so sánh phải đồng nhất.
Lưu ý: nếu giả định tổng thể có phân phối chuẩn với phương sai bằng nhau không đáp ứng được thì bạn có thể dùng kiểm định phi tham số Kruskal-Wallis sẽ để thay thế cho ANOVA.
Levene test
Ho: “Phương sai bằng nhau”
Sig < 0.05: bác bỏ Ho
Sig >=0.05: chấp nhận Ho -> đủ điều kiện để phân tích tiếp anova
ANOVA test
Ho: “Trung bình bằng nhau”
Sig >0.05: bác bỏ Ho -> chưa đủ điều kiện để khẳng định có sự khác biệt…
Sig <=0.05: chấp nhận Ho -> đủ điều kiện để khẳng định có sự khác biệt…
Khi có sự khác biệt thì có thể phân tích sâu hơn để tìm ra sự khác biệt như thế nào giữa các nhóm quan sát.
Cách thực hiện:
Phân tích anova : vào menu Analyze -> Compare Means -> One-Way ANOVA
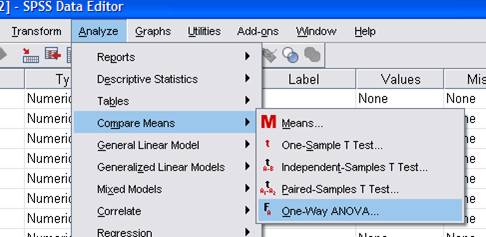
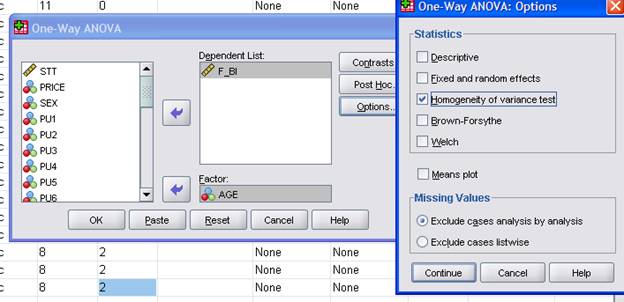
Bấm vào option chọn Homegenety of variance test để kiểm định phương sai đồng nhất.
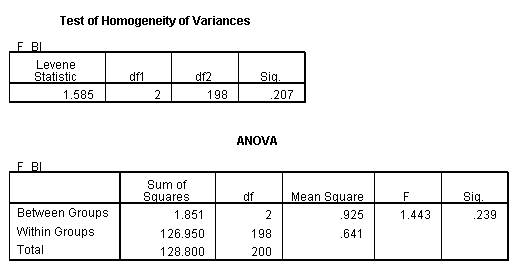
Kết quả ANOVA ra như sau
- Xử lý/ hiệu chỉnh số liệu khảo sát để chạy ra kết quả phân tích nhân tố hội tụ,phân tích hồi quy hồi quy có ý nghĩa thống kê.
- Tư vấn mô hình/bảng câu hỏi/ traning trực tiếp về phân tích hồi quy, nhân tố, cronbach alpha... trong SPSS, và mô hình SEM, CFA, AMOS